🧪 Promptificate: Put Your Prompts in the Lab
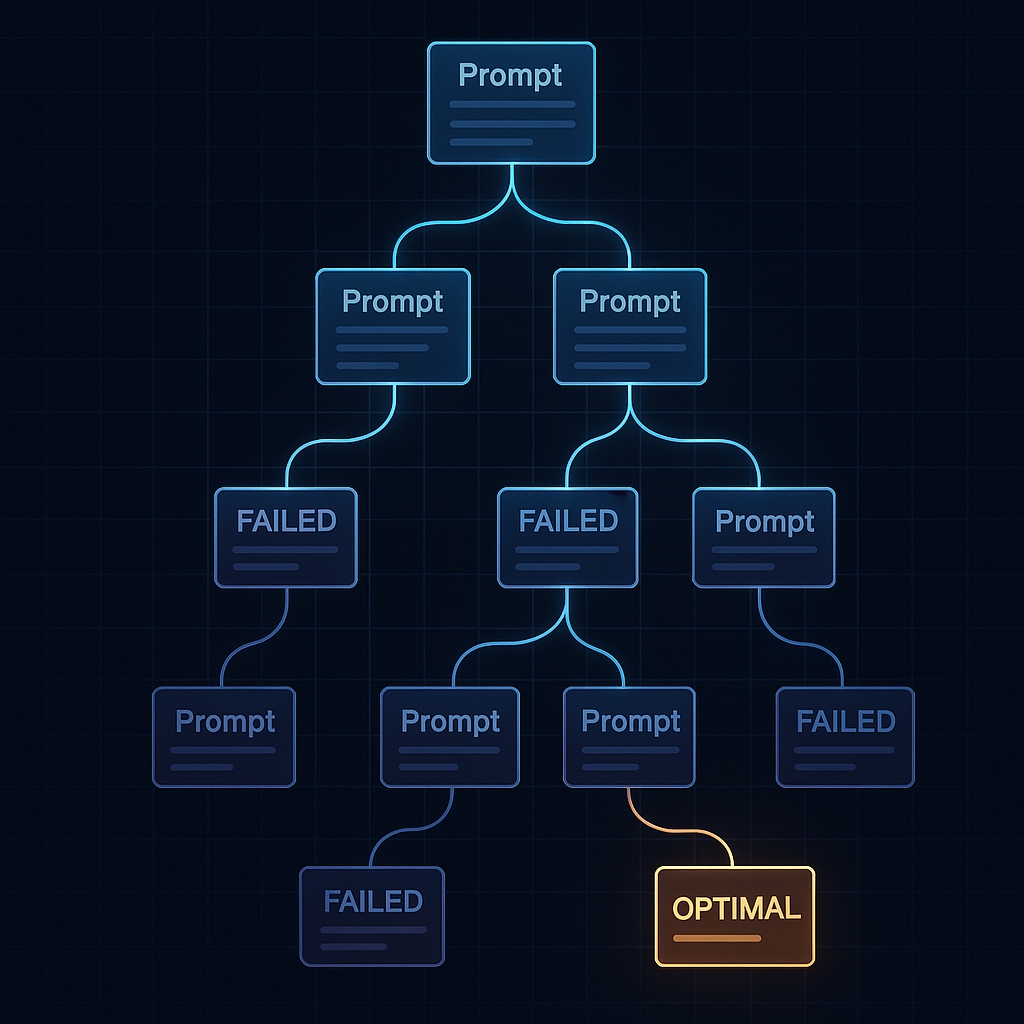
Large-language models are only as good as the text you feed them, yet most teams still hand-tune prompts by gut feel—burning tokens and engineer hours in the process. Promptificate closes that gap by treating prompt design like real R&D:- Score every prompt on a 0–100 scale across clarity, context, structure, safety, and cost.
- Evolve dozens of new variants with genetic algorithms and Monte-Carlo sampling.
- Select the statistically best performer, giving you a data-backed “optimal” prompt—fast.
The Market Gap
- Manual tinkering doesn’t scale Product teams iterate in private docs or ChatGPT chats, with no repeatable benchmarks.
- Model fragmentation is exploding GPT-4o, o3, Claude 4, Gemini 2.5 Pro—each responds differently. You need vendor-agnostic tooling.
- Cost vs. quality trade-offs are invisible A longer prompt might boost accuracy 5 %, but also double your bill. Without metrics, you can’t see the curve.